Due to increasing use of domain specific languages (DSLs), declarative style of modeling is quetly spreading among users of MDE tools. Indeed, it is easy to find examples of declarative DSLs, e.g. at DSM Forums or this blog. There is however a group of users, among which the delarative style of modeling has not managed to spread – transformation developers. I am not sure if it has something todo with the group itself or with the fact that the majority of today’s transformation definition languages (TDL) are still more imperative in style (I am aware of QVT Relations and ATL, but these are rather exceptions than the norm).
There are quite a few good reasons why one would consider using a declarative language for transformation definition: reduction of information content in transformation definitions (and hence higher productivity of transformation developers), more agile DSL evolution, transformation definitions as models, higher compatibility with parallel computing, etc..
Today I would like to share some practical results that illustrate reduction of information content due to use of a declarative language.
CHART vs. Java
The following examples are kindly provided by Maarten de Mol and Arend Rensink from University of Twente. In CHARTER project, they are working on certifiable transformation technology for development of safety-critical embedded systems.
Before proceeding to the examples, here are a few relevant highlights of their technology:
- Partially declarative transformation definition language (CHART): based on graph transformation and intended to be useable by Java programmers.
- Transformation compiler (RDT): given a transformation definition written in CHART, generates its executable implementation in Java. The produced code runs against and transforms user provided data.
Figures 1 and 2 present transformation rules findRich and addPicture respectively. Each figure shows its rule written both in CHART and Java. The important Java methods are match() and update(), which are the translations of the similarly named blocks in CHARTER rules.
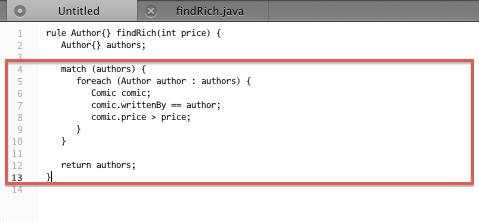
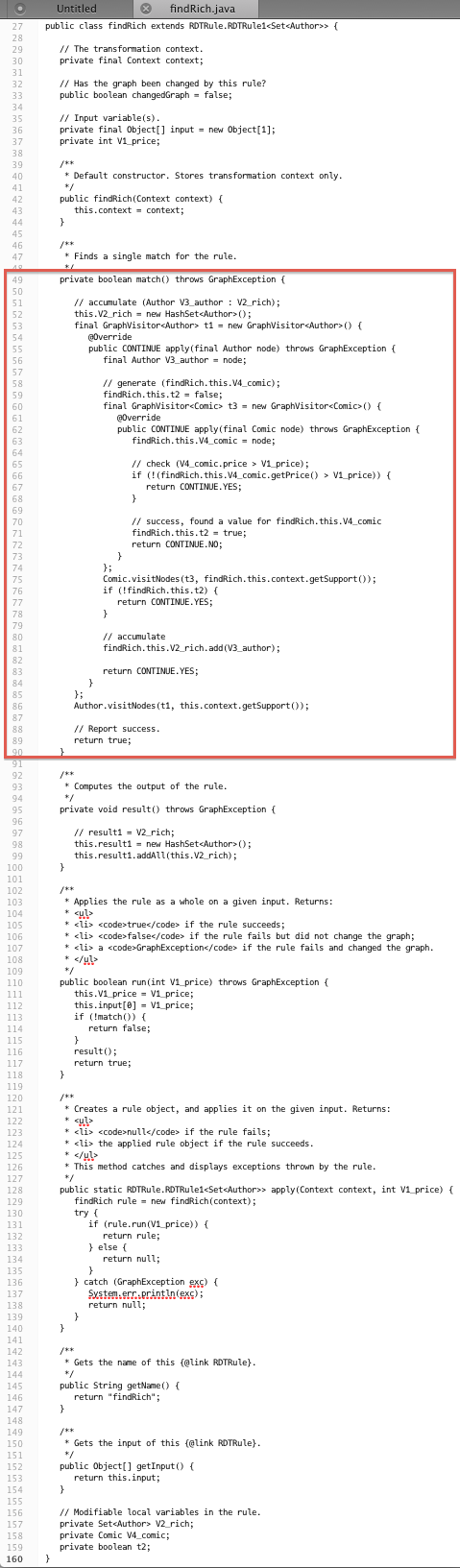
Figure 1: Rule findRich written in CHART (a) and Java (b)
In Figure 1a, a match block counts 10 LOC against 41 LOC in Java (Figure 1b), which constitutes a reduction of information content by 75%.


Figure 2: Rule addPicture written in CHART (a) and Java (b)
In Figure 2a, an update block counts 12 LOC against 65 LOC in Java, an 80% reduction.
Both examples show significant reduction of information content in CHART rules. The reduction is even stronger if one takes into account that Java implementations also have to address technical concerns, which do not exist in CHART rules. In this case reduction is 92% (13 LOC vs. 160 LOC for rule findRich).
In experence of another CHARTER partner, who evaluates CHART/RDT in practice, a CHART transformation definition counted 1024 lines of code against 8000 in Java, an 87% reduction of information content [1]. Author’s own industrial experiences elsewhere with AToM3 GG rules (declarative) and QVT Operational (imperative) agree with the above results as well.
While exact reduction numbers are certainly arguable, the overal trend in the above experiences is that use of a declarative TDL can result in dramatic reduction of information content and manyfold increase of development productivity.
Conclusion
Despite industrial successes of MDE (which are often hidden), it is my experience that model-driven methods have hard times keeping up as organizations evolve. One factor behing this lag is slow speed of transformation development. Practical industrial experiences such as above, show that declarative languages have potential to significantly improve agility of transformation development.
What are your experiences with declarative TDLs and agile language development? Can you share concrete examples or provide references to declarative TDLs?
References
[1] de Mol, M.J. and Rensink, A. and Hunt, J.J. (2012) Graph Transforming Java Data. In: Proceedings of the 15th International Conference on Fundamental Approaches to Software Engineering (FASE 2012), 26-29 Mar 2012, Talinn, Estonia. Lecture Notes in Computer Science. Springer Verlag.

Good argument!I have a little trouble with "reduction of information content": I think it’s more a reduction of noise and increase of signal-to-noise ratio.I think the case is even stronger for model-to-text transformations, since the implementation of those (i.e., code generators) tends to be target language-agnostic in the sense that they simply produce text – which may or may not be valid on a syntactical or even structural level, but you typically only find out after running the transformation and building the entire thing. Also, code generators tend to change much more often IMHO than "real M2M" transformations.This is in any case a hard problem and it might even require automated theorem provers to efficiently check whether a transformations output will conform to a certain language (syntax + validation, etc.) and a certain architecture (frameworks used, etc.). However, there are working solutions out there, e.g. Stratego/SDF from TUDelft does this quite proficiently already – it mixes the abstract syntax of an input model with the concrete syntax of the target language within a template language and does so in a "fill-in-the-blanks" way.
Hi Meinte,I absolutely agree with your comment about the reduction of noise and increase of signal-to-noise ratio. This is what in effect happens. However the tiny issue with that is that essential info (signal) and the incidental info (noise) depend in the intend of the user and hence very subjective. How does one quantify or represent such things? In contrast information content is objective and its reduction is easier to represent (see e.g. http://tinyurl.com/7jbnjyq). Anyway, may be I am wrong, but this was the reason why I chose those words.You make an good point that transformation definitions are also changed. Factoring in change over time, would even make the "info reduction" benefits of declarative languages even stronger. I am not so sure if M2T change much more than real M2M transformation. I think it depends more on the domain of DSLs and transformation. On your last point, I respectfully disagree 🙂 In my experience, usual businesses do not require that high level of confidence in generated code. Any reasonably tested code generator would beat hand-written code in consistency, quality and compliance with target platforms and architectural frameworks.
Maybe we should distinguish between syntactical noise (which could make life easier for the DSL user) and structural noise (boilerplate, stuff that violates DRY, purely related to the target platform, etc. – we should be able to generate this).You’re right: business doesn’t require formal proofs for the correctness of generators. A modest safety nest in the form of an example model and a hand-written/-maintained reference implementation of that model to compare the code generators output against, usually suffices for me.I made the point purely with the Holy Grail of being able to see at a glance whether your transformation code is going to yield valid code, in mind. So, essentially it’s a productivity thing (as you should have more tests than just a lack of error markers in your code), but that tends to impact meta programming less than regular coding – which is where the real benefit is.
Hi Andriy,thanks for your interesting post. Together with Rik Eshuis, I have published about a related comparative study in 2010: see "Transforming Process Models: Executable Rewrite Rules versus a Formalized Java Program" (MODELS, Oslo, http://www.springerlink.com/content/3104x56h48403272/).Together with the people from the Epsilon team, we are about to submit an extended version of this study for journal publication. The tricky yet fascinating part is in ensuring that the transformation codes that you show as evidence realize the same transformation design. Best regards,Pieter
Meinte, very good points. I deliberately avoided the "noise" details to keep the story short and more accessible. Glad to see your passion and ambition – MDE projects really need these qualities :)Pieter, just read the abstract of your paper – it is spot on. I am curious to read full text. Thank you for sharing!
Pieter: "The tricky yet fascinating part is in ensuring that the transformation codes that you show as evidence realize the same transformation design."The CHART/RDT technology from the article is being developed for safety-critical embedded systems. The property that you describe is a must for our intended industries. Unfortunately our project does not have time anymore to address this. I wonder if you have any developed and published ideas on this subject?
Hi Andriy,second try to post a comment here, my first attempt failed, the server was notresponding.As written on MDSN, the DSLs as well as M2M we use in our product aresolely based on declarative style transformations; in short, the basicprinciple is using XML instance declarations which use an underlying model forfeeding. This looks like that: <Programmer SIGNATURE="Person person"> <Name LOCATOR="person/Name"/> <!– read from model below –> <Skills>social, machine language</Skills> <!–some fixed value –> <HourlyRate EXPRESSION="true">some.complicated.JavaCode(here)</HourlyRate></Programmer>We call that "Object Oriented Views", since it is comparable to and may serve similar purposes as Relational Database Views.The technology for that is http://www.xocp.org, we provide it as open source. Themetamodel it uses is just Java classes.Andreas
Andreas, thank you for sharing information about a declarative transformation technology. Can you comment about proven benefits of such technology compared to the traditional imperative transformation development?
Well, I can tell two stories which show why it became our preferred choice.OCP technology did not start out as a planned thing. Indeed, the very first version was nothing else but a convenient way to load test data from XML files, kind of mockup-feeding. Over the years we added several features as needed.For various purposes in our product we needed little languages, foremost for the description of the models we process. In the beginning it was just, "hey let’s use that test data language for a start". It was simple, descriptive, and worked. Actually, it worked so well, that until today we never replaced it with a "real" language. We finetuned OCPs to such an extent, that the XML input looks human readable, compact, and aesthetically.Later, we needed a language for describing M2M transformations. We investigated what was available then, and how to manage it (intermediate files etc.). While thinking over possibilities and complications that where introduced by them, someone got the sudden idea of just using the same language we used for describing the source models, nothing to learn, nothing to manage inbetween (it is simply a dynamic view on the source model), and it is mostly declarative, so you could just write the model as you would anyway.Moreover, since the OCP metamodel is dynamically derived from the Java classes used to load the data, there is no additionaly metamodel-language to learn or to manage, it’s just plain Java.That’s been the first part of the story, why we introduced the technology, and why we stick to it til today.The other half is more concerned with the outside view, i.e. external or a customers’ developer who need to tune or extend the transformation a little. Here, the fact that it is the same modelling language as you use for the source model is a plus, since the language is already known (at least if you work with our product), and it is easy to understand as well.Of course there are limits, and more complicated transformations lead to more complicated transformaion OCPs, but that is obvious, I’d say.So, alltogether, it’s simply we don’t see any advantage in switching to something different, other transformation technologies we know of bring in one or the other kind of burden: less intuitive and readable, additional language to learn (M2M plus metamodel), additional artefacts to manage (intermediate files).
Andreas, thank you for sharing your stories about OCP!